
whisper

1. Сводка
Запускает распознавание речи OpenAI Whisper на аудиоветви процесса и отдаёт файл субтитров или скрытых субтитров. Узел потребляет аудиодорожку, выбранную выше по потоку, и производит дорожку Text, которую узлы ниже по потоку могут смультиплексировать, отгрузить сайдкаром или упаковать рядом с выходом адаптивного стриминга.
2. Когда использовать
- Авто-субтитрирование поставки для доступности, когда у источника нет дорожки субтитров.
- Генерация дорожек скрытых субтитров для адаптивного стриминга HLS или DASH через ccinject, чтобы плеер мог предложить выбор субтитров.
- Подготовка быстрого черновика транскрипции, который редактор может проверить и исправить перед публикацией.
3. Входы
Audio—[]filtergraph.AudioTransform. Аудиопоток, который модель транскрибирует. Подключите аудиоветвь, которую хотите распознать — обычно диалоговую дорожку, выбранную map/audio.Совместимые узлы выше по потоку:
- map/audio — выбирает, какие аудиопотоки идут на выход.
4. Выходы
Text—core.TextTrack. Транскрибированная дорожка субтитров или скрытых субтитров в выбранном Format.Совместимые узлы ниже по потоку:
5. Параметры
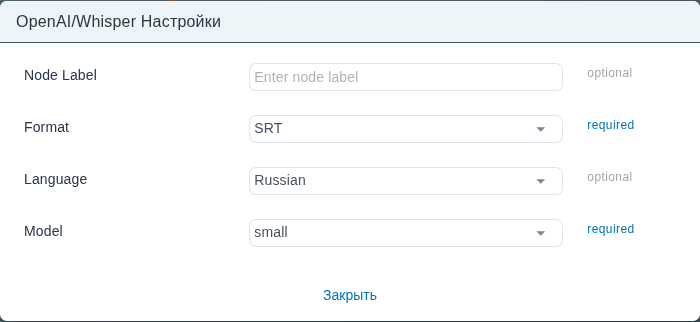
Форма «Настройки» — один столбец с четырьмя полями. Описаны в порядке следования в форме.
Node Label (
string, по умолчанию пусто)Произвольное имя, отображаемое на плитке узла на холсте.
- Что задаёт. Подпись над плиткой; на транскрипцию не влияет.
- Когда менять. Задавайте, когда в одном графе несколько узлов whisper (например, ветви транскрипции по языкам), чтобы каждый был узнаваем с одного взгляда.
Format (
enum, по умолчаниюSRT, обязателен)Формат файла субтитров, который отдаёт узел.
- Что задаёт. Проводной формат произведённой дорожки Text.
SRTдаёт текст SubRip, подходящий для сайдкар-файлов и широкой поддержки плеерами;WebVTTдаёт W3C Web Video Text Tracks, подходящий для упаковки HLS и DASH. - Когда менять. Выбирайте
WebVTT, когда упаковщик ниже по потоку — hls5, hls3 или dash. ВыбирайтеSRTдля сайдкар-доставки, редакторских черновиков или совместимости с настольными плеерами. - Допустимые значения.
SRT,WebVTT.
- Что задаёт. Проводной формат произведённой дорожки Text.
Language (
enum, по умолчаниюAuto, опционально)Двухбуквенный код ISO, подсказывающий язык источника;
Autoдаёт Whisper определить язык из аудио.- Что задаёт. Язык декодирования. Явная установка пропускает шаг автоопределения и принуждает модель транскрибировать на этом языке независимо от того, чем кажется аудио.
- Когда менять. Задавайте, когда аудио на известном одном языке, а короткие
клипы иначе сбивают детектор Whisper — типично для коротких трейлеров,
вставок закадрового голоса и рекламных роликов. Оставляйте на
Autoдля длинного контента и неизвестных источников.
Model (
enum, по умолчаниюsmall, обязателен)Размер модели Whisper для загрузки. Большие модели обменивают время обработки и стоимость GPU/CPU на точность транскрипции.
- Что задаёт. Какой чекпойнт Whisper выполняет транскрипцию. Большие чекпойнты дают лучшую точность слов, особенно на именах собственных и предметной лексике, но дольше работают на минуту аудио и потребляют больше памяти.
- Когда менять. Используйте
smallдля быстрых черновиков транскрипции и массовых прогонов, где грубые субтитры приемлемы. Используйтеmedium, когда поставка не будет проверяться человеком и важна точность — субтитры доступности, архивные транскрипции или субтитры производственного качества. - Допустимые значения.
small,medium.
Соответствие JSON-ключей и названий полей
JSON-ключи opt, которые могут встретиться в файлах процессов, отображаются на
подписи формы так:
| JSON-ключ | Название поля |
|---|---|
format |
Format (srt / webvtt в JSON, SRT / WebVTT в форме) |
language |
Language |
model |
Model |
name |
(не выводится в форме; имя выходного файла выводится из процесса) |
6. Пример
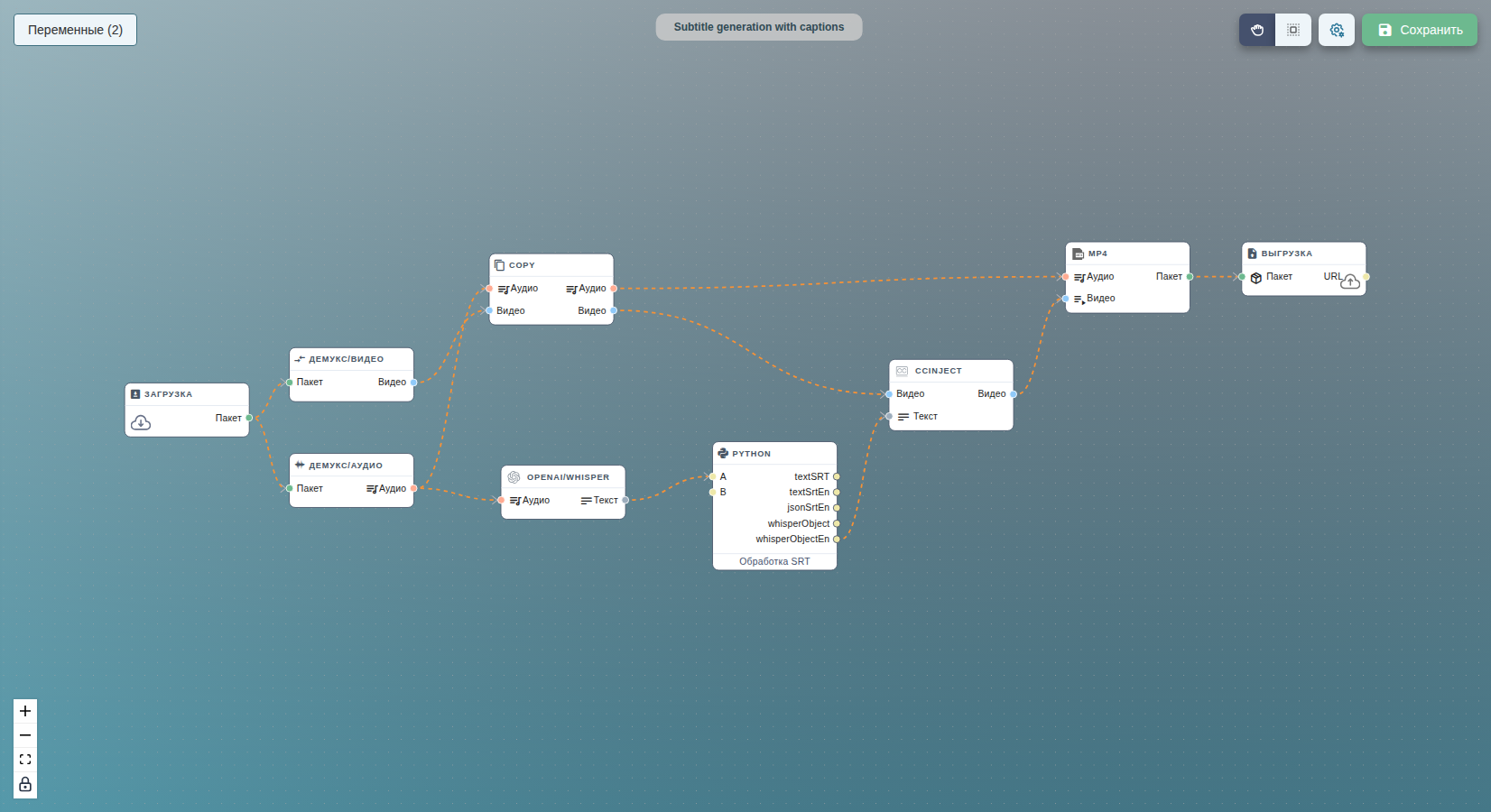
Полный разбор — переменные, настройка каждого узла и ожидаемый результат — смотрите в Adaptive streaming with HLS, DASH and captions.
7. Где используется
- Adaptive streaming with HLS, DASH and captions — транскрибирует диалоговую ветвь в дорожку WebVTT, которую шаг ccinject вкладывает в выходы HLS v3, HLS v5 и DASH.
8. Антипаттерны
- Запуск
medium, когда хватаетsmall. Большая модель в несколько раз медленнее и существенно прожорливее к памяти. Для черновиков транскрипции и массовых партий начинайте сsmallи поднимайтесь, только если точность на выборочном выходе неприемлема. - Транскрипция низкокачественного аудио без фильтра очистки. Фоновый шум, обрезанная речь и сильное сжатие быстро деградируют выход Whisper. Поставьте цепочку аудиофильтров (af/aresample, af/stereo) выше по потоку, чтобы нормализовать частоту дискретизации и раскладку каналов перед транскрипцией, или перережьте аудиоисточник до запуска процесса.
- Расчёт на Whisper для языков, которые он транскрибирует плохо. Модель сильна на широко распространённых европейских и восточноазиатских языках и слабее на малоресурсных. Для критичного к доступности выхода в случае слабого языка считайте дорожку Whisper черновиком и пропускайте её через редакторскую проверку перед отгрузкой.
9. Заметки
Каноническая цепочка доступности для адаптивного стриминга —
map/audio → whisper → ccinject → hls5/dash: выберите диалоговое аудио,
транскрибируйте его в WebVTT, вложите дорожку субтитров в видеопакет, затем
отгрузите через HLS v5 и DASH со встроенным выбором субтитров. Рабочий пример —
Adaptive streaming with HLS, DASH and captions.